MCache: Web Session Clustering
By Mark L. Woodward
February 27, 2007
Copyright © Mohawk Software
2001, 2007
MCache is sort of unique in what it does. It was developed for a
specific class of problem that is ill served, a shared cache system
that isn't necessarily tied to a specific data source. To understand
what MCache does, you need to understand the construction of a
classic high performance web site.
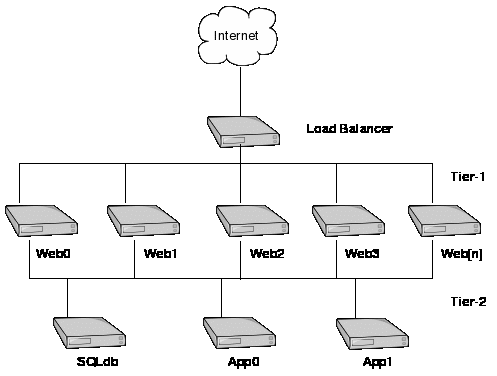
A typical high volume website design is based on a logical
separation of tasks in to multiple levels and servers, where each
successive level gets more specialized and thus harder and/or more
expensive to replicate.
Load Balancer
The load balancer accepts requests from the internet and by using
various algorithms, directs the request, invisibly to the web
browser, to a web server. It could be a Local Director, an Alteon, or
even a Linux LVS system (http://www.linuxvirtualserver.org).
Web Server - Tier-1
The web servers are just any old web servers, IIS, Apache, etc.
They could either be stand-alone or in a cluster, they are designed
to not know or care how they are configured. The same web code that
runs on one machine should be able to run across 100 machines.
The purpose of web servers are to provide presentation and
incidental functions for the end user.
SQL Database and Application Servers - Tier-2
The back-end servers that provide that actual purpose of the site.
They perform banking transactions, record the contents of your
shopping cart when you order, etc.
Classic N-Tier Model
An N-Tier model, as shown in the above web site example, is
designed so that the higher the level, the less critical and more
plentiful the resource. It is the job of higher levels to isolate the
lower levels and perform work that is more easily distributed. This
design works best when the amount of work at the lower levels is much
reduced from that of the higher levels. An architecture may have more
tiers than simply two, but each additional tier can add latency to
requests so there is often a point of diminishing returns. Also,
items like application servers may, themselves, be an N-Tier system.
While this is typically called “scalable,” the design is
limited by the utilization of the lower tiers. A proper architecture
factors this in by caching data acquired from a lower level in the
level requesting the data. In the above example, the web servers
should cache as much data as they can at the web server level and
only request data from the lower level when absolutely needed.
False Scalability
The big problem with this design is false scalability if used
incorrectly. Many web designers think of databases and business logic
servers as sources of infinite performance. When ever they need data,
they think nothing about hitting a lower level. When they want to
store data, no matter how temporary, they use the database without a
second thought.
Unfortunately, the resources are not infinite. No matter how many
web servers you have, if you don't regulate or limit access to the
lower levels, your site will fall apart under heavy load. Sure, you
can add all sorts of additional servers but that just adds cost and
complexity to your system. Proper design reduces complexity and cost
and increases reliability by removing unneeded systems.
The unfortunate truth is that any coherent system, no matter how
scalable, is limited by some logical bottleneck. A good design
balances the tiers as best as possible, but regardless of what you do,
every design has a limit. Scalability is not something you can
add after the fact with extra machines, it is something that happens
BEFORE you start coding.
Sessions and Performance
Web server environments like Java, IIS, and PHP all support the
notion of a web “session.” Put simply, a web session is a block
of data that hangs around from one HTTP request to another. Using web
sessions can dramatically improve site performance and should not be
underestimated.
In the PHP environment, a session is represented by an
alphanumeric string of random characters. The string is used to
access data stored locally on the server. If you use the PHP
defaults, this is typically a file stored in the “/tmp”
directory. The session reference string is stored as cookie in the
user's web browser, each time the user returns to the site, the
cookie is sent, the session data is retrieved from the file in “/tmp”
and the web service can continue on from whence it left off.
By putting data in the session that otherwise would have had to be
retrieved from a database or business logic server, you reduce the
load in the lower tiers. This should ultimately allow your site to
handle more traffic. The session file acts like an elementary caching
mechanism.
Cache Coherency
Nothing comes for free. Once you start using sessions as a cache,
you run into another problem, cache coherency. Put simply, cache
coherency is ensuring that what is in cache accurately represents the
data it is supposed too.
With a single machine, this is easy, the session file is most
likely correct. If you have multiple web servers and each web server
has its own copy of the session, who has the accurate copy? The
answer is: you don't know. I believe this is why most web developers
fail to create web sites that scale properly. Since the “session”
systems don't seem to work across multiple machines, they just ignore
the session system and use a SQL database. The architect should not
allow this, and there are several options to get a number of web
servers to implement a single site with coherent session information.
Sticky Sessions
The easiest solution is the notion of “sticky sessions.” Most
load balancers can “pre-process” and understand HTTP requests and
can be set up to recognize various cookie variables or TCP/IP
addresses and be configured to send repeat sessions to the same
servers.
This is a really simple solution to a potentially difficult
problem. However, it has a few issues: it limits the ability of the
load balancer to properly balance the site because it ties a
particular user or group of users by TCP/IP address to a specific
server, it creates extra load on the load balancer having to parse
the HTTP requests, and if anything happens to the web server (i.e. it
gets hacked) those users lose their session data. As capacity of the
site increases, the load balancer can become the limiting system or
“bottleneck.”
Network File System Based Sessions
The next solution is the most logical
one, use a network file system to share session files across multiple
machines. Any web server in the cluster can use any session, leaving
the load balancer to perform properly and the load balancer doesn't
have “pre-process” the web request.
The problems with network file systems
are many, and NFS in particular has a couple issues: NFS' file
locking is inadequate and can allow corruption of the session data.
NFS is slow and generates a lot of network traffic and can impact the
back end networking infrastructure.
Database Session Table
The next common solution is using a database to store session
information. (Since most web sites have a database, this is usually
easy to do.) Although it isn't as scalable as sticky sessions or as
simple as using an NFS share, it doesn't share their problems either.
The problem with database session managers is the database itself.
Databases just aren't intended to hold simple temporary “cache”
data. They can, of course, but it is not the best utilization of
resources. A good database is a designed to preserve data integrity
at all costs. They are designed to analyze and optimize queries and
use the best methods to create relational joins. The amount of
overhead for the simple “select” and “update” of a simple
session table is like using a sledge hammer to kill a fly.
What's even worse are the characteristics of database performance
in a highly volatile data environment. There are basically two types
of database, three if you count the really broken ones, the first are
the simplistic databases that use locking mechanisms during access,
and the second, the more advanced ones, that use some sort of MVCC
(Multi Version Concurrency)
Locking Databases
A locking database, something like
MySQL, is one in which all requests to the database result in some
sort of lock. A SQL “SELECT” results in a read lock on the table.
Any number of SELECTs may be running at a time, but while they are,
no INSERTs, UPDATEs, or DELETEs can. When an INSERT, UPDATE, or
DELETE is being executed no SELECT statements (or INSERTs, UPDATEs,
and DELETEs for that matter) can be run.
These types of databases are a very bad
choice for session managers because they tend to perform worse when
they are needed most. The higher the volume of traffic to your site,
the more table locking gets in the way.
MVCC Databases
An MVCC database doesn't lock. They
typically use “row versioning.” With a locking database, when an
update is executed, the table is locked, the row to be modified is
found, the data is modified and saved back to disk in place of the
old data, and then the table is unlocked. With an MVCC database, the
latest version of the row to be modified is found, it is modified and
saved to the disk as a new version of the row. The old version and
values remain. No locking happens.
MVCC databases perform much better in a
volatile data environment than do locking databases, but they are not
perfect. The PostgreSQL database, for instance, has a pronounced
problem in a web session scenario. Since previous versions exist
simultaneously with newer versions, each query must search through
older versions to find the correct version. Each UPDATE made to a row
increases the amount of work required to find the correct version of
the row for the next query. For PostgreSQL, the VACUUM command
updates the internal database structures so that they point to the
most recent version, but again, the next update causes a new version
of the row to be added, again adding additional processing to find
the latest version of the row.
To see this behavior in PostgreSQL,
create a table, insert a row. Now, write a quick program to update
the row about 10 or 20 thousand times. By the end of it, you'll see a
lot of disk activity and a huge reduction in performance. Now, update
the row once more and note how long it takes and how much disk access
happens. Run the VACUUM command. Now try to update the row again.
You'll see performance has been restored.
While this seems like an extreme case,
and in some ways may be, but given a busy site with a few thousand
active users, each getting between 5 and 10 pages, on average, per
session, this could easily result in dramatic session table clutter
and slowdown in PostgreSQL. In a busy site, you will need to run
VACUUM quite frequently.
While PostgreSQL has a more pronounced
pathological behavior, most MVCC systems suffer the same problem only
they hide it better. The tell tale sign is disk I/O.
False or “Phantom” Updates
Regardless if you use one or one hundred web servers, phantom
updates will get you if you are not careful. What is a “phantom
update?” Imagine your website is built using HTML frames, your top
level FRAMESET calls out three FRAMEs. The user hits the top level
page, the browser parses the FRAMESET, and issues three simultaneous
HTTP requests, one for each frame page. Each HTTP request gets its
own process or thread on the web server (or servers), each gets the
same session cookie, and each retrieve the same session information.
When each completes their task, they save their session state and
finish.
That may sound like the correct operation, but it is broken and
can lead to lost data or data corruption. Imagine each page
increments a counter in the session. In PHP this may look something
like this:
$_SESSION['count']++;
When the three frame pages are fetched, they each get the same
copy of the session. Let's assume the value of 'count' is “1.' Each
process sees a value of “1,” each will increment their value, and
each increment will result in a value of “2.” At the end of their
processing, each process will save its session data. The result in
the session will end up being that of the last web process to finish.
The value of 'count' will be “2.” This is, in fact, an error.
Starting with “1,” each of the three frame pages incrementing a
counter should result in “4.”
What happened? This is the phantom update problem and it occurs
when data is modified without regard to other processes who may also
be modifying the data. If you were writing a multi-threaded program
you'd use a mutex, semaphore, or critical section to serialize access
to the data. Surprise! web pages can get bit by the same problems as
applications. The PHP “mod_files” session module handles this by
locking the session files with flock() in the “/tmp” directory.
This is another bug that a lot of web sites have but don't even
know it. Many simply use a SQL database to handle the session
information assuming that the database will handle the problem
unaware that they need to lock session information. It isn't the
database's fault, to properly handle sessions using a SQL database
you need to use something like “SELECT * from sessions where
session_key = 'foo' for UPDATE” which will lock the row from other
processes.
Shared Variable Access
The previous “Phantom Update” problem alludes to a much larger
problem that seldom occurs to the web developer or even some of the
more experienced architects. A web site, especially one with multiple
web servers, shares alls of the problems of a parallel processing
environment where just about all non-local data accessed by the code
has the potential to be accessed simultaneously by 2 or more
processes.
This problem is deeper and more insidious than may first appear.
Take, for instance, the common “internet poll.” Some number of
options will be presented for a vote. For the sake of example lets
use three types of beer: Sam Adams, Bud Light, or Pabst Blue Ribbon.
The straight forward approach is almost always wrong.
Frighteningly, the following pseudo code is actually implemented in a
few CMS systems I have seen:
Step 1, get the poll information from the database with a simple
query that returns all the poll items and their count.
$results = sql->query(“SELECT * from
poll_table where poll_name = 'beer_poll'”);
Step 2, increment the counter that represents the user's choice.
$newcount = $results[$selection]['count']+1;
Now Set it back
sql->update(“UPDATE poll_table set count
= $newcount where poll_name = 'beer_poll' and item = '$selection'”);
What happens here is the “phantom update” all over again. Any
number of users could retrieve the same data, increment the same
item, and update the table and lose other poll results. Last one to
execute the update wins.
The only way to implement this poll in an active website, using a
SQL database, is to use a locking mechanism like “SELECT ... FOR
UPDATE” followed by the UPDATE and a COMMIT. Not even the common
“UPDATE poll_table set count=count+1 where poll_name='beer_poll'
and item ='samadams'” works unless your transaction is set for
“serializable.” (The flip-side of the “phantom update” is the
“phantom read” It is basically the same problem, only seen from
the perspective of the reader instead of the writer.)
MCache
MCache is designed to address many of the challenges of a high
volume website. It is sort of a cross between a session manager,
database server, and distributed lock.
Cluster Web Session Manager
The first thing MCache can do for you is make setting up two or
more web servers behind a load balancer a snap. By using the MCache
extension for PHP, multiple web servers can share and access session
information seamlessly with little or no modification to your web
code and with no fussing with load balancers, NFS file servers, or
SQL databases.
MCache takes care of “phantom updates” and “cache coherency”
at the session level with no additional coding by the web
application.
Improve Performance with Caching
With a single web server or a moderate sized cluster of web
servers, MCache improves performance by maintaining an in memory
cache of session information.
With multiple web servers MCache provides improved overall
performance by reducing load on a back end database and MCache
typically out performs SQL databases on the same hardware because it
is not a general purpose application, it is designed to perform a
very specific number and type of operations.
Manages Shared Variable Access
Shared variables are one of the more difficult constructs in a web
site, and are easily managed with MCache. Simply by using the MCache
API, almost all the concurrency issues one needs to deal with are
handled by MCache. For instance, the previous “beer_poll” example
can be implemented in PHP this easily:
$pcreated = mcache_getdata('beer_poll');
if(!$pcreated)
{
# Create poll object if not there
mcache_create('beer_poll', 'poll_class', '');
mcache_setdata('beer_poll', 'created');
}
# Voting in Poll;
if($selection)
mcache_inc('beer_poll', $selection);
#display poll
$polldata = mcache_get_array('beer_poll');
display_var("Beer Poll",
$polldata);
The above code creates a “beer_poll” object, and then
facilitates voting. It really is that easy, and it works, and it
works on one or many machines quickly and reliably.
Sharing Across Application Bases
While not a completely new or unique idea, MCache can facilitate
the sharing of data across application code bases in much the same
way that a SQL database would. While PHP is well supported, the API
is provided as a set of C function calls. Almost any application that
can use a C library can use MCache.